
音视频信号数字化后所产生的数据速率相当大,例如一分钟的双声道立体声.采样频率为11.025kHz,8bit量化,其数据速率达176.4kbit/s,存储容量需要1.323MB,而数字化激光唱盘的CD-DA红皮书标准是采用44.1kHz采样,16bit量化,双声道一分钟其存储容量达10.584MB。
视频信息数字化后数据量更大,以分量编码的数字视频信号为例,其数据率高达216Mbit/s,在此情况下,1小时的电视节目需要近80GB的存储容量,要远距离传送这样一路高速率的数字视频信号,通常要占用108~216MHz的信道带宽,显然这样大的数码率在现有的数字信道中传输或在现有的媒体上存储,其成本是十分昂贵的。因此为了提高信道利用率和在有限的信道容量下传输更多的信息,必须对音视频数据进行压缩。
1. 一、数据压缩的理论依据
在数据压缩技术中Shannon所创立的信息论对数据压缩有着极其重要的指导意义,它一方面给出了数据压缩的理论极限,一方面指明了数据压缩的技术途径。
由信息论基础知识可知信源概率分布越均匀其熵越大;反之其熵越小。离散无记忆信源只要其概分布不均匀就存在着信息的冗余,因而就存在着数据压缩的可能性。而信源压缩编码的基本途径之一,就是在一定信源概率分布条件下,尽可能使编码平均码长接近于信源的熵,减少冗余信息。
信源往往并不是无记忆的,其前后出现的信源符号常常具有一定的相关性。两信源符号间的相关性越大,冗余也越大,因此,数据压缩的另一个基本途径则是去除信源中各信源符号间的相关性。
2. 二、限失真压缩编码
由信息论基础知识可知,信源冗余来自信源本身的相关性和信源概率分布的不均匀性。因此,通过去除信源的相关及改变信源概率分布模型,则可达到压缩数据量的目的。限失真压缩编码即是在允许解码后信号有一定失真的情况下,通过去除信源的自相关来达到压缩数据的目的。在允许失真不超过某一限度时,压缩编码的比特率是受限的,存在着一个下限,这个下限由率失真函数来定义。
率失真理论虽然没有给出怎样达到比特率下限的具体方法,但从理论上指明了方向。即在给定信号允许失真度的条件下,为了减少信号传输的比特率,应尽量减小传输信号的方差。目前,在音视频编码中普遍采用的预测编码和变换编码,正是根据这一理论对原始音视频信号进行适当处理,使处理后信号的方差减小,最终达到压缩编码的目的。
3. 三、无失真压缩编码
预测编码和变换编码都是基于去除样值间的相关性而达到数据压缩的目的。如果信源已经是无记忆的,即各样值间已没有相关性或相关性很小。这时只要各事件出现的概率不相等,该信源就仍然有冗余度存在,就还有进一步进行数据压缩的可能性。无失真压缩编码的基本原理则是去除信源的概率分布不均匀性,使编码后的数据接近其信息熵而不产生失真,因此,这种编码方法又叫熵编码。另外,由于这种编码完全基于信源的统计特性因而也可称其为统计编码。无失真压缩编码的方法主要有:基于信号样值概率分布特性的Huffman编码、算术编码和基于信号样值相关性的游程编码。
1.Huffman编码
变字长编码的最佳编码定理:在变字长编码中,对于岀现概率大的信息符号编以短字长的码,对于概率小的符号编以长字长的码。如果码字长度严格按所对应符号出现概率大小逆顺序排列,则平均码字长度一定小于其他任何符号顺序排列方式。
Huffman编码是根据可变长度最佳编码定理,应用Huffman算法而得到的一种编码方法。可以证明,在给定符号集和概率模型时,没有任何其他整数码比Huffman码有更短的平均码长,也即它是一种最优码。
虽然Huffman码是变长的,码流中又没有分隔码字的标识符,但由于它的无歧义性,完全能够正确地恢复原信源所输出的符号序列来。
需要注意的是,由于Huffman构码过程的最基本依据是信源的离散概率,如果信源的实际概率模型与构码时所假设的概率模型有差异,实际的码长将大于预期值,编码效率将下降。
2.算术编码
算术编码是另一种利用信源概率分布特性、能够趋近熵极限的编码方法。尽管它也是对出现概率大的符号采用短码,对出现概率小的符号采用长码,但其编码原理与Huffman编码却不相同。而且在信源概率分布比较均匀的情况下其编码效率高于Huffman编码。它和Huffman编码的最大区别在于它不是使用整数码。算术编码的特点在于
(1)在Huffman编码中,后续符号的码字只是简单地附加到已编好的码字串之后,并不改变已有的码字串。而在算术编码中,后续符号的编码有可能因为进位而引起已编好的码字串的改变。
(2)在Huffman编码中,最短的码字长度为1比特,所以即使对最常出现的符号进行编码也需在已编好的码字串的基础上增加1比特。而在算术编码中,对累计概率为0的符号编码时不增加已编好的码字串的长度。因此,算术编码时只要将出现概率最大的符号置于累计概率为0的位置,便可大大降低码字串长度。
(3)在算术编码中,随着概率子空间的不断划分,区间长度L越来越小,用来表示它的数字位数越来越长,增加了实现该算法的难度;另外,完成算术编码和解码需进行乘法和除法运算,同样增加了实现该算法的复杂度,进而提高了成本。
3.游程编码
由于音视频信号中各样值间一般都存在相关性,特别是由计算机生成的图像和大部分二值图像,它们往往在某些区域具有相同的像素值。游程编码的主要方法就是在某个特定方向上将样本值相同的若干像素或声音样本用一个游程长度和一个样本值来表示。如沿水平扫描线上的一串m个样值具有相同的数值n,则只要传输(n,m)即可。游程编码对误码较为敏感,为防止误码扩散应采用行、列同步的方法将差错控制在一行、一列之内。
4. 四、音频压缩编码技术
对于不同类型的音频信号而言,其信号带宽是不同的,如电话音频信号为200Hz~3.4kHz,调幅广播音频信号为50Hz~7kHz,调频广播音频信号为20Hz~15kHz,激光唱盘音频信号为10Hz~20kHz。随着对音频信号音质要求的增加,信号频率范围逐渐增加,要求描述信号的数据量也就随之增加,从而带来处理这些数据时间和传输、存储这些数据的容量增加。
1.音频信号压缩编码方法
一般来说,音频信号的压缩编码主要有以下几种主要类型:
(1)波形编码
波形编码是在信号采样和量化过程中考虑到人的听觉特性,使编码信号尽可能与原输入信号匹配,又能适应人的应用要求,如全频带编码(包括脉冲编码调制PCM,瞬时、准瞬时压扩PCM,自适应差分ADPCM等);子带编码(包括自适应变换编码ATC、心理学模型等);矢量量化。波形编码的特点是在高码率条件下可获得高质量的音频信号,适于高保真度语音和音乐信号的压缩技术。
(2)参数编码
参数编码是将音频信号以某种模型表示,再抽出合适的模型参数和参考激励信号进行编码;声音重放时,再根据这些参数重建即可,这就是通常讲的声码器(Vocoder)。参数编码压缩比很高,但计算量大,且不适合高保真度要求的场合。用此类方法构成声码器的有:线性预测(LPC)声码器、通道声码器(Channel Vocoder)、共振峰声码器(Format Vocoder)等。
(3)混合编码
混合编码是一种吸取波形和参数编码的优点,进行综合的编码方法,如多脉冲线性预测MP-LPC,矢量和激励线性预测VSELP,码本激励线性预测CELP,短延时码本激励线性预测编码LBCELP,长时延线性预测规则码激励RPE-LTP等。
2.不同质量要求时的音频编码技术选择
(1)电话质量的音频压缩编码
电话质量语音信号频率规定在300Hz~3.4kHz,如采用标准的脉冲编码调制PCM,当采样频率为8kHz,8bit量化时,所得数据速率为64kbit/s,即一个数字话路。CCITT制定的PCM标准G.711,速率为64kbit/s,采用非线性量化,其质量相当于12bit线性量化。
电话信号的自适应差分脉冲编码调制ADPCM标准G.721,速率为32kbit/s,这一技术是对信号和它的预测值的差分信号进行量化,同时再根据邻近差分信号的特性自适应改变量化参数,从而提高压缩比,又能保持一定信号质量。因此ADPCM对中等电话质量要求的信号能进行高效编码,而且可以在调幅广播和交互式激光唱盘音频信号压缩中应用。
为了适应低速率语音通信的要求,必须采用参数编码或混合编码技术,如线性预测编码LPC,矢量量化VQ,以及其他的综合分析技术。其中较为典型的码本激励线性预测编码CELP实际上是一个闭环LPC系统,由输入语音信号确定最佳参数,再根据某种最小误差准则从码本中找出最佳激励码本矢量。CELP具有较强的抗干扰能力,在4~16kbit/s传输速率下,即可获得较高质量的语音信号。短时延码本激励线性预测编码LD-CELP的标准G.728,速率16kbit/s,其质量与32kbit/s的G.721标准基本相当。采用长时延线性预测规则码本激励RPE-LTP标准GSM,速率为13kbit/s。
(2)调幅广播质量的音频压缩编码
调幅广播质量音频信号的频率在50Hz~7kHz范围。G.722标准是采用16kHz采样,14bit量化,信号数据速率为224kbit/s,采用子带编码方法,将输入音频信号经滤波器分成高子带和低子带两个部分,分别进行ADPCM编码,再混合形成输出码流,224kbit/s可以被压缩成64kbit/s,最后进行数据插入(最高插入速率达16kbit/s),因此利用G.722标准可以在窄带综合服务数据网N-ISDN中的一个B信道上传送调幅广播质量的音频信号。
(3)高保真环绕立体声音频压缩编码
高保真环绕立体声音频信号频率范围是50Hz~20kHz,采用44.1kHz采样频率,16bit量化进行数字化转换,其数据速率每声道达705kbit/s。国际标准化组织ISO和CCITT联合制定的MPEG标准,成为国际上公认的高保真环绕立体声音频压缩标准。MPEG音频第一和第二层次编码是将输入音频信号进行采样频率为48kHz,44.1kHz,32kHz的采样,经滤波器组将其分为32个子带,同时利用人耳掩蔽效应,根据音频信号的性质计算各频率分量的人耳掩蔽门限,选择各子带的量化参数,获得高的压缩比。MPEG第三层次是在上述处理后再引入辅助子带,非均匀量化和爛编码技术,再进一步提高压缩比。MPEG音频压缩技术的数据速率为每声道32~448kbit/s,适合于CD-DA光盘应用。
5. 五、视频压缩编码
1.视频信息的冗余
虽然表示图像需要大量的数据,但图像数据是高度相关的。一幅图像内部以及视频序列中相邻图像之间有大量的冗余信息。对于一幅二维图像,我们可以注意到图像中的许多部分的灰度或颜色差别并不是太大,某些区域是均匀着色或高度相关的。例如图像的背景可能是一堵墙,它是均匀上色的或显示出规则的模式。这称为空间相关或空间冗余。对于没有场景切换或镜头快速推拉摇移的视频序列,画面中的背景一般并无变化,只有移动的物体产生画面的差异,因而各帧图像间的差别极小,即视频序列中的图像是高度相关的。这称为时间相关或时间冗余。静止图像压缩的一个目标是在保持重建的图像的质量可以被接受的同时,尽量去除空间冗余信息。对于活动视频压缩,在去掉空间冗余的同时去除时间冗余,可以达到较高的压缩比。
除空间冗余和时间冗余外,在一般的图像数据中,还存在着其他各种冗余信息,主要表现为以下几种形式:
(1)信息熵冗余
信息熵冗余也称为编码冗余。由信息论的有关原理可知,为表示图像数据的一个像素点,只要按其信息熵的大小分配相应比特数即可。然而对于实际图像数据的每个像素,很难得到它的信息熵,因此在数字化一幅图像时,对每个像素是用相同的比特数表示,这样必然存在冗余。
(2)结构冗余
在有些图像的部分区域内存在着非常强的纹理结构,或是图像的各个部分之间存在有某种关系,例如自相似性等,这些都是结构冗余的表现。
(3)知识冗余
在有些图像中包含的信息与某些先验的基础知识有关,例如在一般的人脸图像中,头、眼、鼻和嘴的相互位置等信息就是一些常识。这种冗余我们称为知识冗余。
(4)视觉冗余
在多数情况下,重建图像的最终接收者是人的眼睛,为了达到较高的压缩比,可以利用人类视觉系统的特点得到高压缩比。人类的视觉系统对于图像的注意是非均匀和非线性的,特別是人类的视觉系统并不是对于图像中的任何变化都能感知。例如图像系数的量化误差引起的图像变化在一定范围内是不能为人眼所察觉的。
2.压缩编码
(1)预测编码
预测编码可以在一幅图像内进行(帧内预测编码),也可以在多幅图像之间进行(帧间预测编码)。预测编码基于图像数据的空间和时间冗余特性,用相邻的已知像素(或图像块)来预测当前像素(或图像块)的取值.然后再对预测误差进行量化和编码。这些相邻像素(或图像块)可以是同行扫描的。也可以是前几行或前几帧的,相应的预测编码分别称为一维、二维和三维预测。其中一维和二维预测是帧内预测,三维预测是帧间预测。
帧内预测编码一般采用像素预测形式的DPCM,其优点是算法简单,易于硬件实现,缺点是对信道噪声及误码很敏感,会产生误码扩散,使图像质量大大下降。同时,帧内DPCM的编码压缩比很低。因此现在已很少独立使用,一般要结合别的编码方法。帧间预测编码主要利用活动图像序列相邻帧间的相关性。即图像数据的时间冗余来达到压缩的目的,可以获得比帧内预测编码高得多的压缩比。帧间预测编码作为消除图像序列帧间相关性的主要手段之一,在视频图像编码方法中占有很重要的地位。帧间预测编码一般是针对图像块
的预测编码,它采用的技术有帧重复法、阈值法、帧内插法、运动补偿法和自适应交替帧内/帧间编码法等,其中运动补偿预测编码现已被各种视频图像编码标准采用,得到了很好的结果。这类图像编码方法的主要缺点在于对图像序列不同的区域,预测性能不一样.特别是在快运动区,预测效率较差。
预测编码的关键在于预测算法的选取,这与图像信号的概率分布很有关系,实际中常根据大量的统计结果采用简化的概率分布形式来设计最佳的预测器,有时还使用自适应预测器以较好的刻画图像信号的局部特性,提高预测效率。
(2)变换编码
与预测编码技术相比,消除图像数据空间相关性的一种更有效的方法是进行信号变换。变换编码通常是将空间域相关的像素点通过正交变换映射到另一个频域上,使变换后的系数之间的相关性降低。在变换后的频域上应满足:所有的系数相互独立;能量集中于少数几个系数上;这些系数集中于一个最小的区域内。尽管图像变换本身并不带来数据压缩,但由于变换后系数之间相关性明显降低,图像的大部分能量只集中到少数几个变换系数上,采用适当的量化和矯编码可以有效地压缩图像的数据量。而且图像经某些变换后,系数的空间分布和频率特性有可能与人眼的视觉特性匹配,因此可以利用人类视觉系统的生理和心理特点来得到较好的编码系统。
K-L变换是在以上思路下构造出来的最佳线性变换方案。它是用数据本身的相关矩阵对角化后构成的。这种变换将产生完全不相关的变换系数。K-L变换虽然是均方误差准则下的最佳变换,但在实际编码工作中,人们更常采用离散余弦变换(DCT,Discrete Cosine Transform)变换。DCT变换是在现行变换编码方法中,对大多数图像信源来说,最接近K-L变换的方法。
对变换后图像系数的编码一般采用门限编码加区域编码的形式。以DCT为例,根据变换系数的能量分布,可以将图像划分为不同的区域。其中变换后幅值较大的图像系数大多集中于图像块的左上角。与其他系数相比,这些低频系数具有的能量最大.包括了图像的大部分内容,在变换图像中的地位最重要,应使它们的量化误差最小。同样,对于图像块的其他区域,也应采用与该区域相配的量化和编码形式。这种按能量分布对不同区域采用不同量化编码的技术就称为区域编码。另一方面,变换图像中有许多系数的幅度很小,只具有原图像中很小比例的能量,对图像质量影响甚微,因此一般采用设定阈值的方法,置小于阈值的变换系数为零,从而大大提高编码效率。经门限和区域编码后,变换图像的大部分系数为零,如何采用有效的方法将非零系数和零系数组织起来,在带来最少冗余的同时保证最大的连零系数出现概率,是变换图像编码中的又一关键问题。在DCT图像编码方法中,对变换系数进行Zig-Zag排序非常巧妙地解决了这一问题,但对有些图像变换方法,这种技术并非最佳。
在一般图像中,对应边缘轮廓的位置附近含有大量高频信息,它们相对于原图像是非常局部的,代表了图像数据的精细结构。按人眼的视觉特性,这些边缘轮廓信息对于图像的主观质量很重要,在编码时应给予特别考虑。然而由于传统的正交变换时频局域性很差,变换后的系数失去了对原图像精细结构的描述.从变换图像得不到图像边缘轮廓等局部信息.因此在量化编码时无法采用特殊的方法。而且在传统的变换图像编码方法中,大多是靠丢弃高频系数来提高压缩比的,从而导致图像的边缘轮廓模糊,严重影响复原图像的主观质量.
这是传统变换编码方法的缺点之一。传统变换编码方法的另一缺点是提高编码压缩比时会出现块效应。这是因为为降低变换算法的运算复杂度和提高编码效率,传统图像变换均采用了分块变换技术。图像块大,相关性就高,压缩比也就大。但是块的尺寸太大又会丢失数据的平稳性,从而引入误差,包括失去高频细节、引入沿物体边界的噪声和可见的DCT图块边界。实验证明,块大小为16x16或8x8是较好的选择。
要实现一个实用的变换编码系统,需要4个步骤。第一步是选择变换类型,DCT变换是得到最广泛应用的一种类型。第二步是选择方块的大小,较好的方块尺寸是8X8或16X16。第三步是选择变换系数,并对其进行高效的量化,以便传输或存储。第四步是对量化系数进行比特分配,通常使用Huffman编码或游程编码。
(3)具有运动补偿的帧间预测编码
在图像传输技术中,活动图像特别是电视图像是被关注的主要对象。活动图像是由时间上以帧周期为间隔的连续图像帧组成的时间图像序列,它在时间上比在空间上具有更大的相关性。消除活动序列图像在时间上的冗余度是图像压缩编码的一个重要途径。与消除图像中相邻像素间的空间冗余度一样,消除序列图像在时间上的相关性也可采用预测编码的方法,即不直接传送当前帧的像素值,而是传送当前帧的像素值x和其前一帧或后一帧的对应像素x’之间的差值,这称为帧间预测。当图像中存在着运动物体时,简单的预测不能收到好的效果,例如在下图1中当前帧与前一帧的背景完全一样,只是小球平移了一个位置,如果简单地以k-1帧像素值作为k帧的预测值,则在实线和虚线所示的圆内的预测误差都不为零。
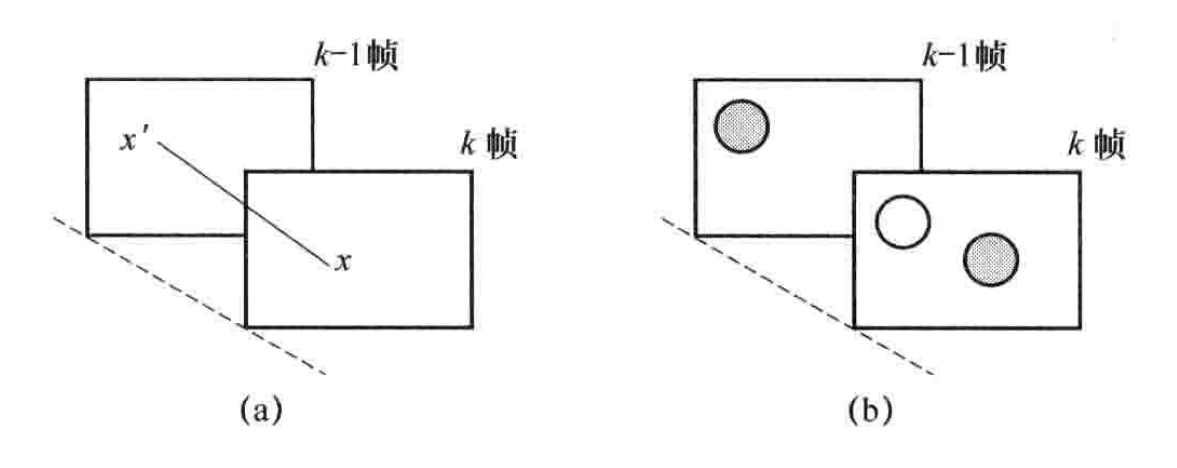
图1 帧间预测与具有运动补偿的帧间预测
如果已经知道了小球运动的方向和速度,可以从小球在^-1帧的位置推算出它在k帧中的位置来,而背景图像(不考虑被遮挡的部分)仍以前一帧的背景代替,将这种考虑了小球位移的k-1帧图像作为k帧的预测值,就比简单的预测准确得多,从而可以达到更高的数据压缩比。这种预测方法称为具有运动补偿的帧间预测。
具有运动补偿的帧间预测编码是视频压缩的关键技术之一,它包括以下几个步骤:首先,将图像分解成相对静止的背景和若干运动的物体,各个物体可能有不同的位移,但构成每个物体的所有像素的位移相同,通过运动估值得到每个物体的位移矢量;然后,利用位移矢量计算经运动补偿后的预测值;最后对预测误差进行量化、编码、传输,同时将位移矢量和图像分解方式等信息送到接收端。
(4)具有运动补偿的帧间内插编码
在具有运动补偿的预测编码系统中,利用了活动图像帧间信息的相关性,通过对相邻帧图像的预测误差进行编码而达到压缩数据的目的。运动补偿技术的引入,大大提高了预测精度,使传输每一帧图像的平均数据量进一步降低。在此系统中图像的传输帧率并没有变化.仍与编码前的帧率一样。然而在某些应用场合如可视电话、会议电视等,对图像传输帧率的要求可适当降低,这就为另外一种活动图像压缩编码方法一帧间内插提供了可能。活动图像的帧间内插编码是在系统发送端每隔一段时间丢弃一帧或几帧图像,而在接收端再利用图像的帧间相关性将丢弃的帧通过内插恢复出来,以防止帧率下降引起闪烁和动作的不连续。
在帧间预测中引入运动补偿的目的是为了减少预测误差,从而提高编码效率。运动估值的不准确会使预测误差加大,从而使传输的数据率上升.但接收端据此位移矢量和预测误差解码不会引起图像质量下降。而在帧间内插中引入运动补偿的目的,是使恢复的内插帧中的运动物体不致因为内插而引起太大的图像质量下降。这是由于在丢弃帧内没有传送任何信息,要确定运动物体在丢弃帧中的位置必须知道该物体的运动速度。运动估值的不准确,将导致内插出来的丢弃帧图像的失真。另外,在帧间内插中的位移估值一般要对运动区的每一个像素进行,而不是对一个子块;否则,内插同样会引起运动物体边界的模糊。因此,在帧间内插中较多使用能够给出单个像素位移矢量的像素递归法。
除了上述介绍的几种目前应用最为广泛的压缩编码方法外,矢量量化编码、子带编码、小波变换、分层编码、分形编码、模型编码等均是近年来研究十分活跃的编码方法。




